To finish the trilogy (Dataops, MLops), let’s talk about DataGovOps or how you can support your Data Governance initiative.
- The origin of the term : Datakitchen
We must give credit to Chris Bergh and his team DataKictchen. You should visit their website, you will find incredible good stuff there. This article was published in October 2020 with this title : “Data Governance as Code”. The idea behind that is you should “actively promotes the safe use of data with automation that improves governance while freeing data analysts and scientists from manual tasks”. The article is illustrated with many examples. It is well illustrated and it is really the fouding article.
Let’s try to give another illustration of this idea.
2. The Dataops Heritage
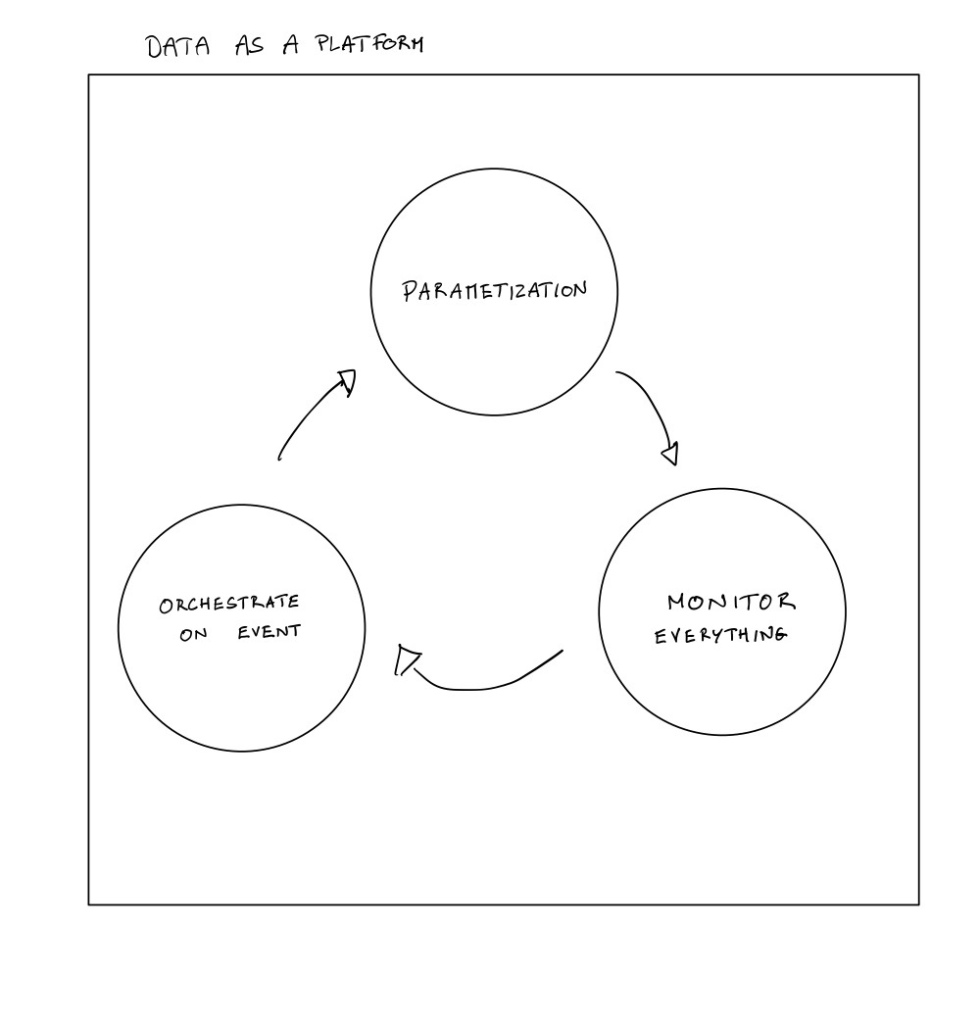
In my previous article, I have described the loop around the devops part of dataops.
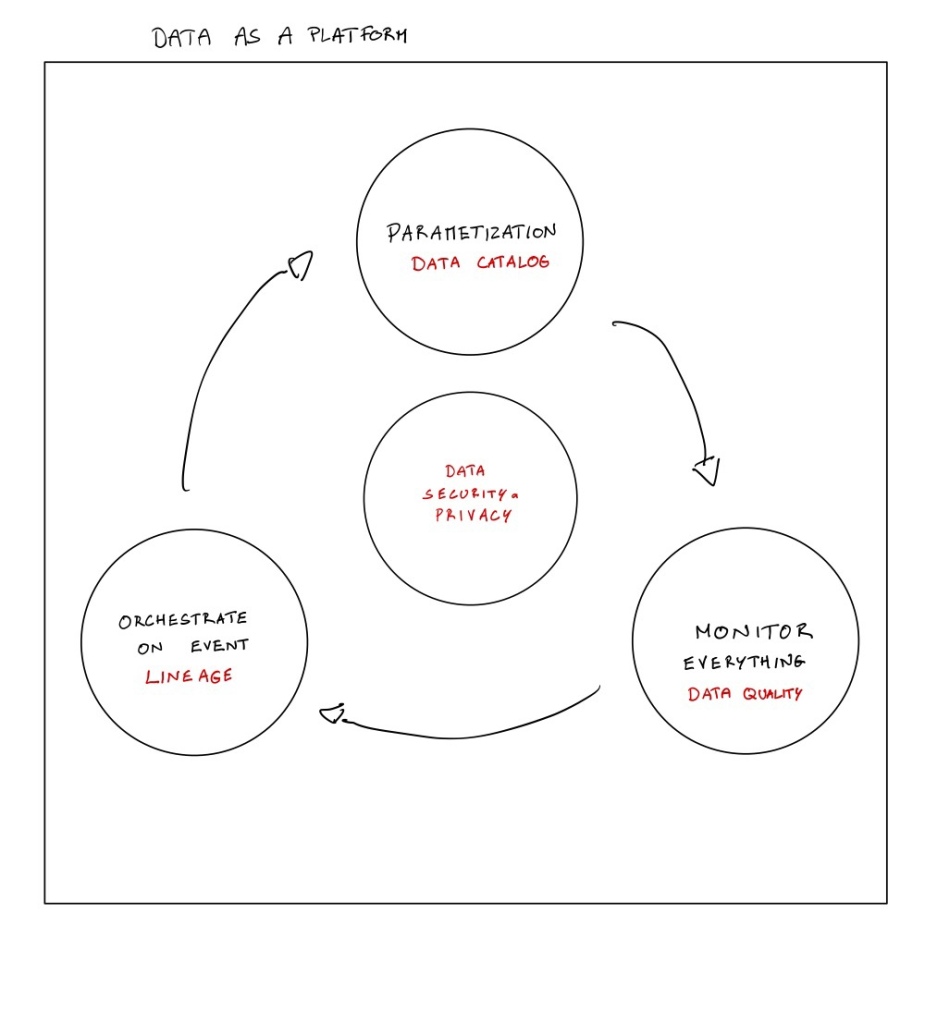
- Parametization (every new data object is a parameter) to Data Catalog (every new data object will generate by itself all the needed metadata)
- Monitor everything (every step is monitored and tested) to Data Quality/Observability (every step comme with data quality check)
- Orchestrate on event (each workflow is on event) to Data Lineage (every step of the workflow is recorded every time).
As mentioned in the DataKitchen article, it is deployed automatically with code. It is not an extra work by reading the database schema or based on your ETL. In every step,we do not just read, transform and write data, we are also doing that with the metadata.
Last part, it was added the data security and privacy part. Every data governance policy about this topic must be read by a code to act in your data platform (access management, masking, etc..)
3. How does it help the Data Governance
You will find a good definition here : ‘True data governance puts the rules in place and aligns the organization so data is not a potential liability”. To do that, Data Governance will need a lot of information about the data itself (inventory, users, measurement of data quality, access management, usage, etc…) to be able to align People, Process and Policies. Data Governance will also need to be able to implement the policies directly in the data platform or be able to enrich the data generated. This is the role of datagovops to reduce the cycle time between policies and their deployment.
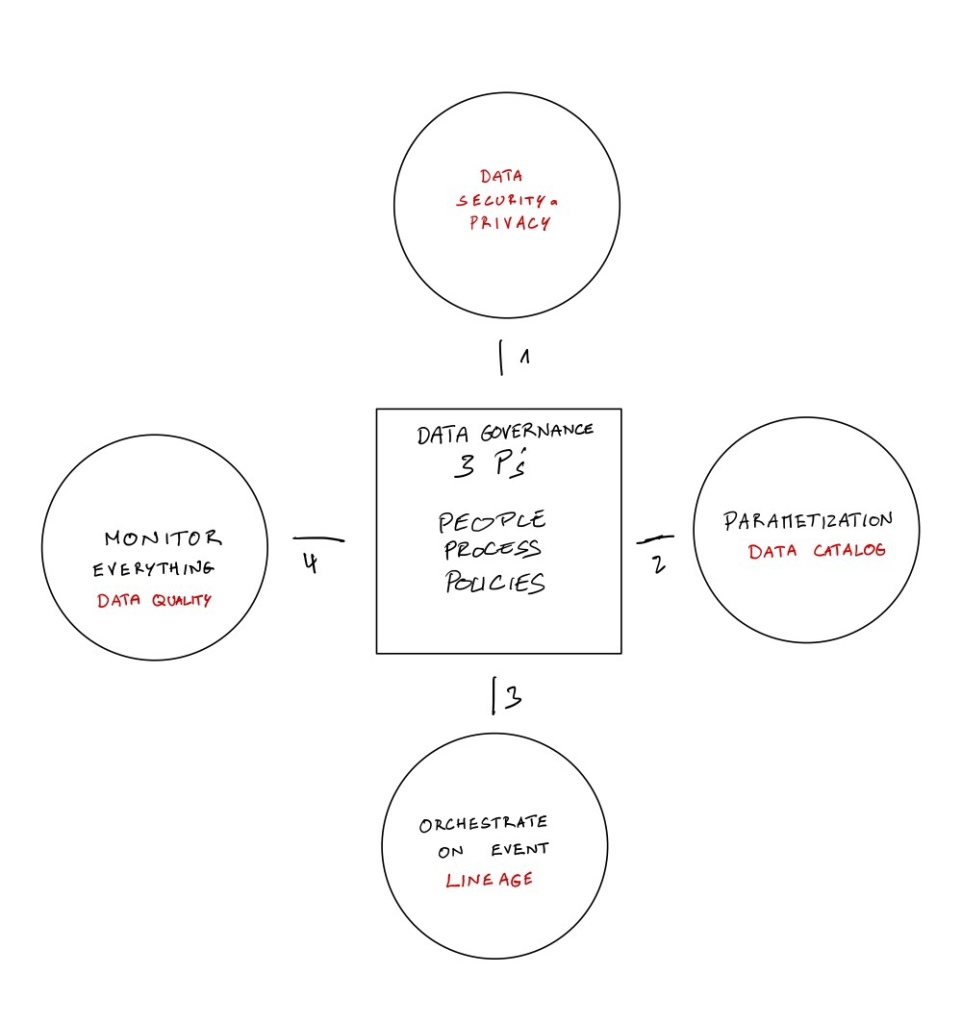
4. DataGovOps or the 5W2H approach
5W2H is for Why, Who, What, Where and When + How and How many/much. This is a common way to ensure that you are covering every aspects of a subject. It is a useful tool when it is about your data because you have many questions :
- Why the data pipeline is broken ?
- Who has an access to this Data ? Who used this table ?
- What data do we have ? What is the data quality check done on this table ?
- Where is this table ? Coming from which source ?
- When this table was updated ?
- How this metric or table has been generated ?
- How many tables do we have ? How many users ? etc…
Starting a DataGovOps aims to anwser to all these questions easily and always without any additional manual tasks. Knowing what’s happening in your data is maybe the first real sign that Data Governance is in place.

